DeepDetect release v0.16.0
DeepDetect v0.16.0 was released last week. Below we review the main features, fixes and additions.
DeepDetect v0.16 was released last week. With support for object detector training with torch C++ and a choice of backbone networks.https://t.co/uDw9ejQdiQ
— jolibrain (@jolibrain) April 30, 2021
DeepDetect is our production toolset that aggregates our advances solving real-world automation problems.#DeepLearning #AI
In summary
- Object detector (Faster-RCNN, RetinaNet) training from Torch C++ backend
- FP16 inference on GPU with Torch backend
- Madgrad optimizer with Torch backend
Fixes & Improvements
- Improved memory allocation with TensorRT backend
- Fixed case-sensitivity of service names
- Improved object detection RefineDet model input image size control
- Ability to load partial model with the Torch backend
- Fixed in-memory crops in chains
Docker images
- CPU version:
docker pull jolibrain/deepdetect_cpu:v0.16.0 - GPU (CUDA only):
docker pull jolibrain/deepdetect_gpu:v0.16.0 - GPU (CUDA and Tensorrt) :
docker pull jolibrain/deepdetect_cpu_tensorrt:v0.16.0 - GPU with torch backend:
docker pull jolibrain/deepdetect_gpu_torch:v0.16.0
All images available on https://hub.docker.com/u/jolibrain

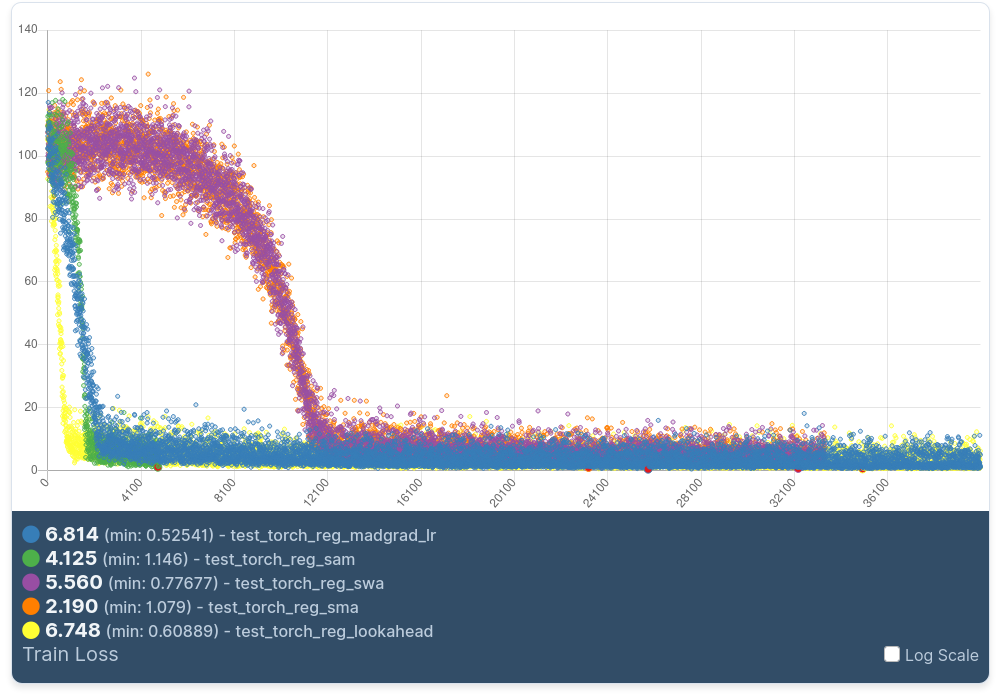
Training with Madgrad
Madgrad is a novel optimizer described in Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization, that brings faster convergence without loss of precision. It is a very good paper that highlights the steps the authors went through to uncover the proper changes to existing dual averaging methods.
We're introducing an optimizer for deep learning, MADGRAD. This method matches or exceeds the performance of the Adam optimizer across a varied set of realistic large-scale deep learning training problems. https://t.co/6NGmJzHlZp pic.twitter.com/SttsLQeQTd
— Facebook AI (@facebookai) March 30, 2021
In our implementation with DeepDetect, Madgrad is implemented in C++ for the torch backend as solver_type: MADGRAD, and has support for additional options, such as lookahead and stockastic weight averaging.
This is yet another very recent improvement from the academia that keeps DeepDetect optimizers at the fringe of the state of the art. And at Jolibrain we do this for a reason: automation is our motto, and thus improving optimizers directly, automates and improves all models and hyper-parameter finding at once. It does not solve all difficulties, but it pushes the results overall into the right direction.
To use Madgrad with DeepDetect Server or Platform alike is made very simple: use "solver_type":"MADGRAD" to your training call with the torch backend.
FP16 inference with Torch
Very easy to use on any torch model, with "datatype":"fp16" added to the "mllib" JSON object of a predict call.
Training a Faster-RCNN
DeepDetect is adding support for object detection models to its torch backend. This is not always made easy due to the mix of Python and C++ of existing implementations. Prior to integration to DeepDetect, the full model and its layers are either exported to torchscript or converted to C++.
Faster-RCNN and RetinaNet are now supported both in inference and training.
Another short blog post will detail the steps and results associated with these models.