Transformer architectures are coming to vision tasks
There’s a new breed of computer vision models in the making. This change is mostly due to the coming of the originally NLP oriented Transformer architectures to computer vision tasks.
Recent advances of 2020 in this domain include the Vision Tranformer (ViT / Google) and the Visual Transformer (Berkeley / Facebook AI) for image classification. And the DETR (Facebook) and Deformable DETR (SenseTime) architectures for object detection.
These approaches and architectures have a few elements in common:
- They are pretty simple architectures that rely on multi-head self-attention as a generalization of convolutions
- They have good FLOPs/accuracy trade-off, slightly better than their convolutional counterparts.
- They are easy to scale, i.e. without having to accomodate the size of convolutional kernels, etc…
The main drawback is that of Transformers themselves: training the global attention heads is slower and requires much more data samples than local convolutional kernels.
On the Relationship between Self-Attention and Convolutional Layers
— hardmaru (@hardmaru) January 11, 2020
This work shows that attention layers can perform convolution and that they often learn to do so in practice. They also prove that a self-attention layer is as expressive as a conv layer.https://t.co/44I1uOd4LF pic.twitter.com/iqioR9eXzU
Two *necessary* conditions (often met in practice):
— Jean-Baptiste Cordonnier (@jb_cordonnier) January 10, 2020
(a) Multiple heads, ex: 3x3 kernel requires 9 heads,
(b) Relative positional encoding to allow translation invariance.
Each head can attend on pixels at a fixed shift from the query pixel forming the pixel receptive field. 2/5
Vision Transformer with DeepDetect
DeepDetect Server & Platform now support the ViT architecture natively in C++ with libtorch (the C++ subset of Pytorch). Our implemention follows that of Ross Wightman’s in pytorch image models.
ViT basically is BERT that eats image patches as inputs instead of word tokens. Simple, well understood and efficient then.
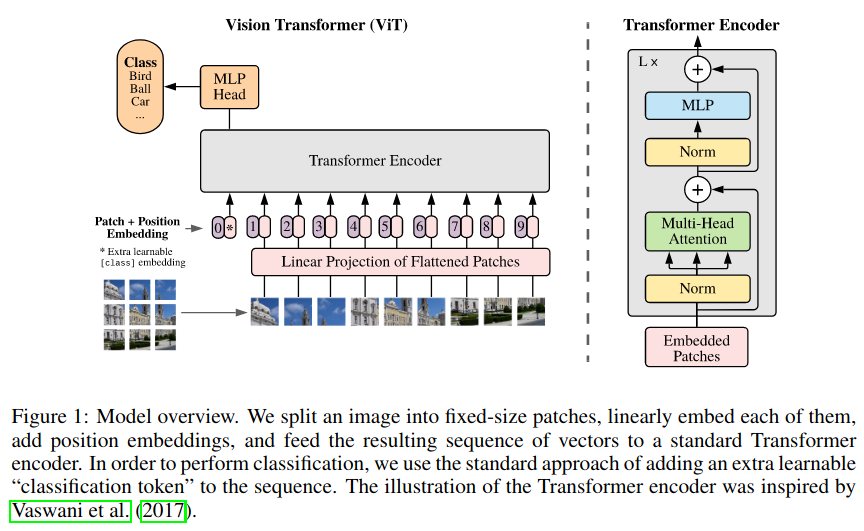
ViT in DeepDetect comes several flavors:
- 3 architectures as in the paper,
base,largeandhugewith support for16x16and32x32input patches. - 1
tinyexperimental architecture - Weights from pytorch image models and Google are supported.
Experimenting with ViT
To quickly finetune a cats/dogs image classification model with ViT and DeepDetect server:
Prepare the data and model directory
mkdir /path/to/cats_dogs_data cd /path/to/cats_dogs_data wget https://www.deepdetect.com/dd/datasets/cats_dogs.zip unzip cats_dogs.zip mkdir /path/to/cats_dogs_vit cd /path/to/cats_dogs_vit wget https://www.deepdetect.com/models/vit_torch/vit_base_p16_224.nptCreate a service
# service creation curl -X PUT http://localhost:8080/services/testvit -d ' { "description": "image", "mllib": "torch", "model": { "repository": "/path/to/cats_dogs_vit" }, "parameters": { "input": { "connector": "image", "db": true, "height": 224, "mean": [ 128, 128, 128 ], "std": [ 256, 256, 256 ], "width": 224 }, "mllib": { "dropout": 0.1, "gpu": true, "gpuid": 0, "nclasses": 2, "template": "vit", "vit_flavor": "vit_base_patch16" } }, "type": "supervised" } 'Train a ViT model
# train a model curl -X POST http://localhost:8080/train -d ' { "async": false, "data": [ "/path/to/dogs_cats_orig/train" ], "parameters": { "input": { "db": true, "mean": [ 128, 128, 128 ], "shuffle": true, "std": [ 256, 256, 256 ], "test_split": 0.1 }, "mllib": { "nclasses": 2, "net": { "batch_size": 32, "test_batch_size": 32 }, "resume": false, "solver": { "base_lr": 1e-05, "iter_size": 1, "iterations": 20000, "solver_type": "ADAM", "test_interval": 500 } }, "output": { "measure": [ "f1", "acc", "cmdiag" ] } }, "service": "testvit" } '
Training then converges very quickly:
[2020-12-11 13:12:50.445] [testvit] [info] base_lr: 1e-05
[2020-12-11 13:12:50.445] [testvit] [info] clip: false
[2020-12-11 13:12:50.445] [testvit] [info] Training for 20000 iterations
[2020-12-11 13:12:50.445] [torchlib] [info] Opened lmdb /data1/beniz/models/cats_dogs_vit/train.lmdb
[2020-12-11 13:13:02.138] [testvit] [info] Iteration 20/20000: loss is 0.30064
[2020-12-11 13:13:13.258] [testvit] [info] Iteration 40/20000: loss is 0.140192
[2020-12-11 13:13:24.837] [testvit] [info] Iteration 60/20000: loss is 0.0917499
[2020-12-11 13:13:36.938] [testvit] [info] Iteration 80/20000: loss is 0.0654708
[2020-12-11 13:13:49.247] [testvit] [info] Iteration 100/20000: loss is 0.0300346
[2020-12-11 13:14:01.533] [testvit] [info] Iteration 120/20000: loss is 0.0332479
[2020-12-11 13:14:13.825] [testvit] [info] Iteration 140/20000: loss is 0.0182476
More Transformers are coming up
Study of the ViT is till ongoing in the academia, very interesting times!
We added the visualisation of the attention patterns of Vision Transformer!https://t.co/zKZGRLCTmp
— Jean-Baptiste Cordonnier (@jb_cordonnier) December 7, 2020
Some heads learn translation equivarient attention to extract patches at fixed shifts. Other heads rely on color similarity or maybe more semantic features deeper in the network. pic.twitter.com/fHIXRQR1fS
Compared to our model:
— Jean-Baptiste Cordonnier (@jb_cordonnier) December 7, 2020
▶︎ No image prior knowledge in the learned positional encodings: 2D relative -> 1D absolute
▶︎ ViT-Base/16 is bigger: 6 -> 12 layers, 9 -> 12 heads, 2 -> 16 patch size
▶︎ Trained on larger images from ImageNet/JFT instead of CIFAR-10
DeepDetect via its C++ torch backend is expected to support more of the recent developments around the Tranformers and multi-head attention developments.