Get the AI Server Running Anywhere
in Seconds
# Setup server architecture
export ARCH=cpu # gpu also available
# Setup models directory
export MODELS=/path/to/models
# Pull the docker image
docker pull docker.jolibrain.com/deepdetect_${ARCH}
# Start the AI server
docker run -d -u $(id -u ${USER}):$(id -g ${USER}) -v ${MODELS}:/opt/models -p 8080:8080 docker.jolibrain.com/deepdetect_${ARCH}curl -X GET http://localhost:8080/info
# Output
{
"head": {
"branch": "master",
"commit": "15c577976ae920fb71973d2f5686c9fdd12716bc",
"method": "/info",
"services": [],
"version": "0.1"
},
"status": {
"code": 200,
"msg": "OK"
}
}Comes in many flavors
Spin a server up on Cloud, Desktop and embedded devices alike

50+ Pre-Trained Models
Ready to Use
For Object Detection, Image tagging, Sentiment Analysis, OCR & more
Load a Deep Neural Network model with a single call
Every model loads as a Service.
Send data to Service to get predictions in milliseconds.
# Load a pre-trained model
curl -X PUT http://localhost:8080/services/detection_600 -d '{
"description": "object detection service",
"model": {
"repository": "/opt/models/detection_600",
"create_repository": true,
"init":"https://deepdetect.com/models/init/desktop/detection_600.tar.gz"
},
"parameters": {
"input": {
"connector":"image"
}
},
"mllib": "caffe",
"type": "supervised"
}'
# Send data over for processing
curl -X POST 'http://localhost:8080/predict' -d '{
"service": "detection_600",
"parameters": {
"output": {
"confidence_threshold": 0.3,
"bbox": true
},
"mllib": {
"gpu": true
}
},
"data": [
"/data/example.jpg",
"/data/example2.jpg"
]
}'








From Deep Neural Networks to Gradient Boosted Trees, on CPU and GPU alike.
- CSV pre-processing
- On-the-fly data augmentation for images
- Audio spectrograms
- BoW and character-based text inputs
 Music
Music Photo
Photo File
File CSV
CSV Timeseries
TimeseriesJSON in / JSON out
Send JSON messages from within your applications, use the JSON output programmatically.
Mustache templating allows shaping the output to fit any sink application (e.g. Elasticsearch, …).
# Send an image over for processing
curl -X POST 'http://localhost:8080/predict' -d '{
"service": "detection_600",
"parameters": {
"output": {
"confidence_threshold": 0.3,
"bbox": true
},
"mllib": {
"gpu": true
}
},
"data": [
"/data/example.jpg"
]
}'
{
"status": {
"code": 200,
"msg": "OK"
},
"head": {
"method": "/predict",
"service": "detection_600",
"time": 60
},
"body": {
"predictions": [
{
"classes": [
{
"prob": 0.8248323798179626,
"bbox": {
"xmax": 487.2122497558594,
"ymax": 351.72113037109375,
"ymin": 521.0411376953125,
"xmin": 301.8126220703125
},
"cat": "Car"
} ],
"uri": "/data/example.jpg"
}
]
}
}
API Clients
Clients for external applications

Pure C++ for best Performances
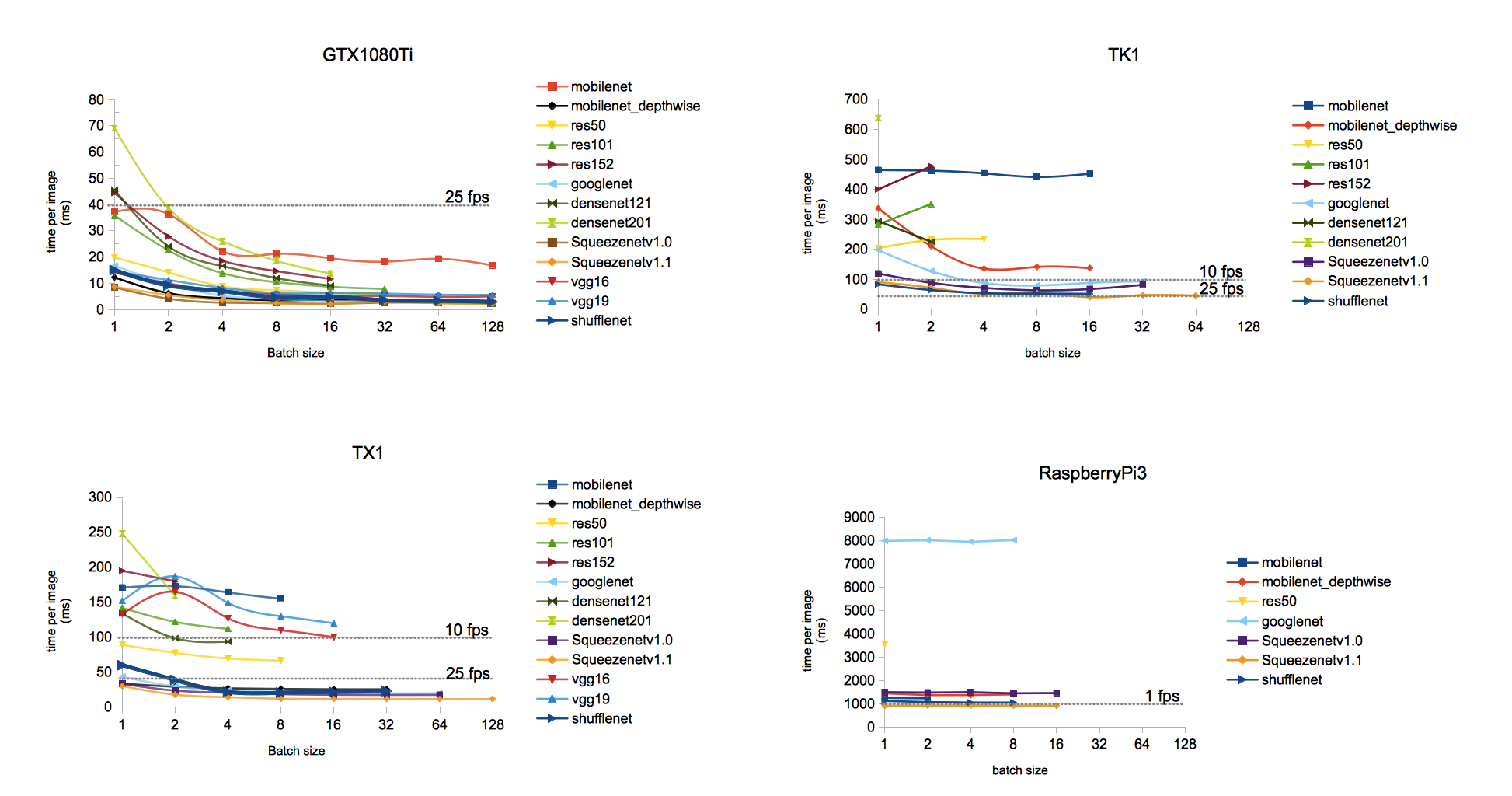
Uncompromised Performances on GPU and CPU
From Cloud to Desktop and Edge, the best in-production performances. Full C++-11 Open Source server eases deployment with top performances from virtual to bare-metal.

 Join our Gitter chat
Join our Gitter chat

Subscribe to our occasional newsletter and keep up to date on new DeepDetect features and changes.