Benchmarking code
Deep neural models can be considered as code snippets written by machines from data. Benchmarking traditional code considers metrics such as running time and memory usage. Deep models differ from traditional code when it comes to benchmarking for at least two reasons:
- Constant running time: Deep neural networks run in constant FLOPs, i.e. most networks consume a fixed number of operations, whereas some hand-coded algorithms are iterative and may run an unknown but bounded number of operations before reaching a result.
- Parallelizsation: When run on GPUs, deep neural network operations can be heavily parallelized with no change in the code. This is a good property that not all networks or hand-crafted pieces of code exhibit.
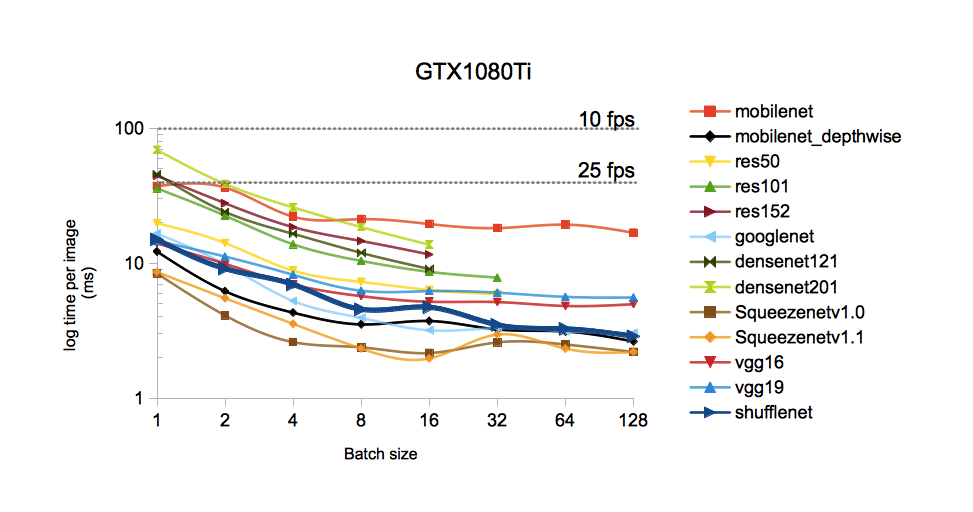
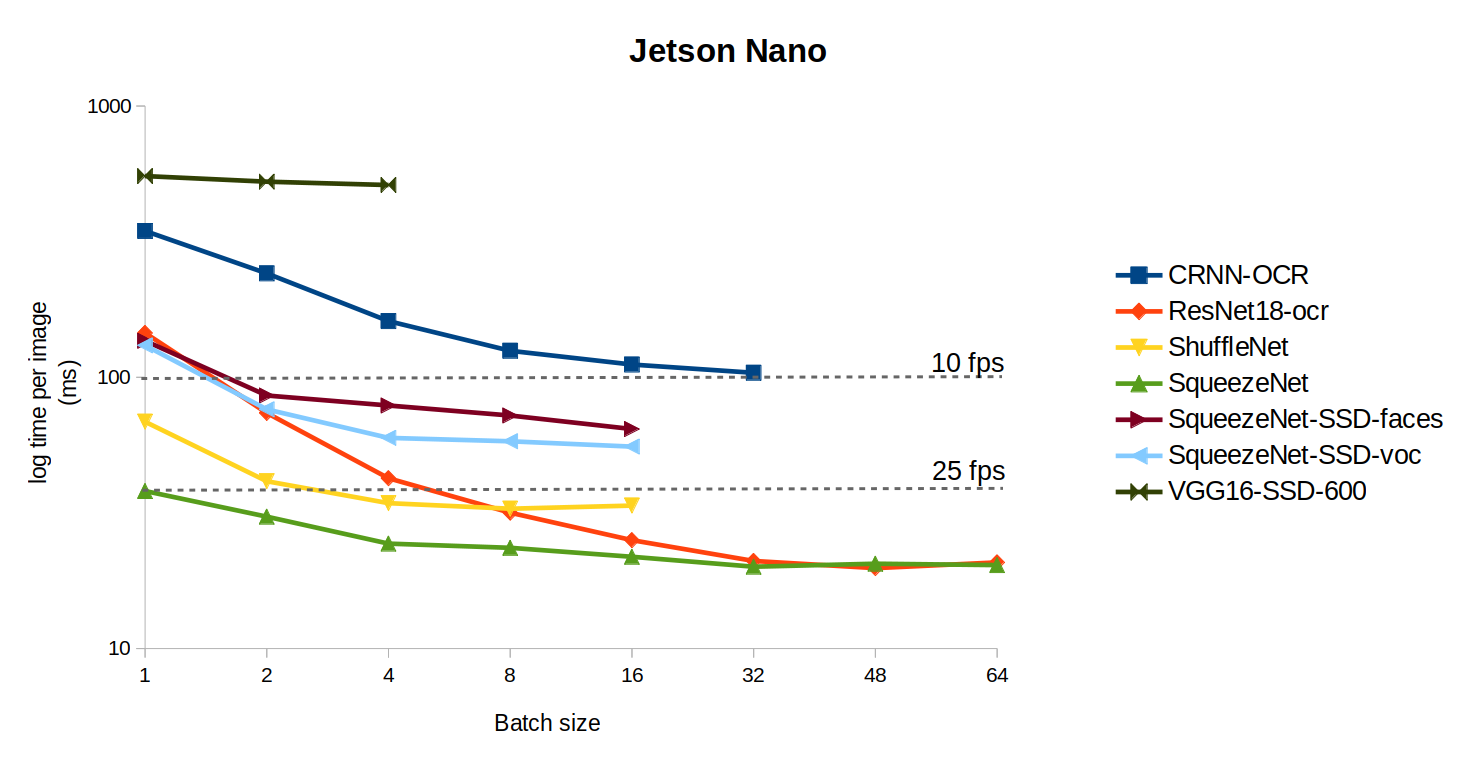
Additionnally, one of the great advantages of neural nets is that they offer an almost continuous trade-off between FLOPs and accuracy. In other words, given a dataset and a metric, there exist a very large (if not infinite) number of neural wiring or architectures that exhibit a growing number of FLOPs, and thus accuracies.
The main rough law stands that more FLOPs yields better accuracy, up to a plateau.
Deep model benchmarks
For these reasons, it is important to benchmarks many architectures, and many levels of parallelism (i.e. batch size) and memory consumption at every step of a problem solving. This can be done as follows:
- FLOPS: Measure the number of parameters and FLOPs of every architecture
- Accuracy: Measure the accuracy of every architecture wrt the problem at hand
- Inference time: Measure the inference time wrt the number of inputs sent in parallel (i.e. the batch size).
DeepDetect allows to do all this easily since our aim is to build models quickly and safely, and choose the best models, context & parameters for production.
FLOPs and parameters
Let us create a service based on a previously trained model:
curl -X PUT http://localhost:8080/services/detection_600 -d '{
"description": "object detection service",
"model": {
"repository": "/path/to/detection_600",
"create_repository": true,
"init":"https://deepdetect.com/models/init/desktop/images/detection/detection_600.tar.gz"
},
"parameters": {"input": {"connector":"image"}},
"mllib": "caffe",
"type": "supervised"
}'
DeepDetect reports the models FLOPs and number of parameters twice:
Once in the server logs
[2020-12-21 16:58:12.036] [detection_600] [info] Net total flops=37871679488 / total params=48670656 [2020-12-21 16:58:12.037] [detection_600] [info] detected network type is detection [2020-12-21 16:58:12.037] [api] [info] HTTP/1.1 "PUT /services/detection_600" 201 1827msVia the API:
http://localhost:8080/services/detection_600{ "body": { "description": "object detection service", "jobs": [], "mllib": "caffe", "mltype": "detection", "model_stats": { "data_mem_test": 0, "data_mem_train": 0, "flops": 37871679488, "params": 48670656 }, "name": "detection_600", ... "status": { "code": 200, "msg": "OK" } }
Above is a 37 GFLOPs model, an object detector for 600 classes. Its architecture is a modified ssd_300 model with a ResNet set of heads for the detail.
Inference and optimal batch size
DeepDetect also allows benchmarking models for finding the optimal batch size that yields the fastest inference call. This is typically targeted at GPUs since they heavily parallelize operations. CPUs are of less interest since increasing the batch size usually leaves the inference time per input unchanged.
Let us benchmark the model created above. The benchmarking tool is bench.py in https://github.com/jolibrain/deepdetect/tree/master/clients/python/dd_client:
Get the set of benchmark images
wget https://deepdetect.com/stuff/bench.tar.gz tar xvzf bench.tar.gz cd bench find . -name *.jpg > ../list_bench.txtRun the benchmark
cd deepdetect/clients/python/dd_client/ python bench.py --host localhost --port 8080 --sname detection_600 --img-width 300 --img-height 300 \ --gpu --remote-bench-data-dir /path/to/bench/ --max-batch-size 32 --list-bench-files /path/to/list_bench.txt \ --npasses 20 --detection --csv-output bench_detection_600.csvPlot the results

Benchmark shows a 42ms inference time with batch size 1, to 13ms per image with batch size 32, on a desktop GPU with TensorRT.