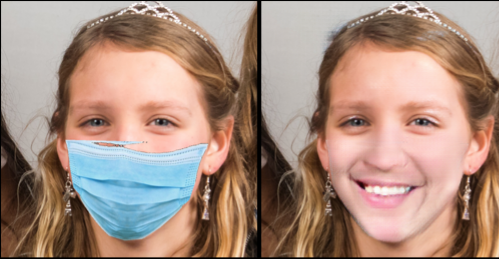
Having fun with https://t.co/Y7NXTdxTlV removing masks... #GAN #DeepLearning pic.twitter.com/VTUMO9j4Lh
— jolibrain (@jolibrain) March 20, 2021
This post shows a somewhat frivolous application of our JoliGAN software, that removes masks from faces. We use this example as a proxy to much more useful industrial and augmented reality applications (actually completely unrelated to faces, etc…).
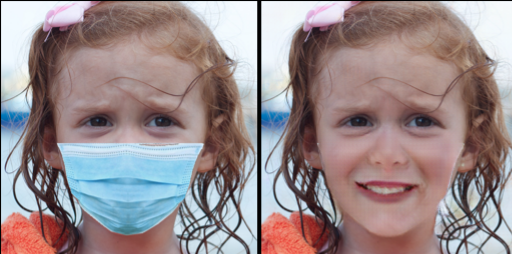
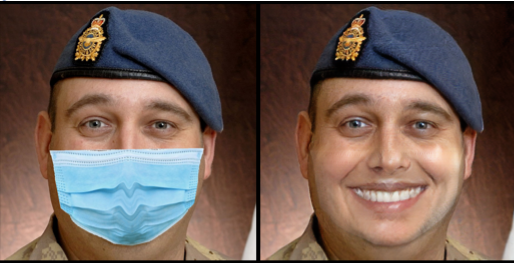
Some result samples are below.


At Jolibrain we solve industrial problems with advanced Machine Learning, and we build the tools to help us fullfil this endeavour.
One common and useful tooling is the ability to turn data from one domain to another, and most espectially images. This has a whole variety of applications:
- Turn synthetic data into real-world looking (we say distributed) data
- Turn an object into another (think augmented reality)
- Fillup a missing piece of data
And this list is far from being exhaustive. This a part of a subfield of Machine Learning called Domain Adaptation. Many recent advances in this field rely on Generative Adversarial Networks (GANs).
Now what is most interesting in industry is the ability to very precisely control what to modify in images of a domain A so that it looks like images of a domain B.
So domain A can be synthetic data, thinks road images from a video game, and domain B real road photographs. Or domain A can be faces with masks, and domain B faces without masks.
Now the fun application is to take images of domain A, faces with masks, and turn them into faces without masks. This means building a deep neural network that actually replaces the pixels of the mask with pixels that form the missing a plausible version of the missing part of the face!
Once such a model is built, it can easily be used in applications with DeepDetect. Below, we skim through the whole process.
Dataset
For building a data set of faces wearing masks, we use a semi-synthetic dataset from the MaskedFace-Net repository. This dataset takes faces from the Flickr Faces HQ (FFHQ) dataset and arranges fake masks on them. It does so by detecting face keypoints, and drawing a mask accordingly.
It is an interesting dataset since it pretty much exactly describes the process that is used in more industrial applications:
- Generate a dataset cheaply as domain A
- Get real-world data as domain B
- Train a GAN to turn this dataset into images that look like domain B
This allows training to turn synthetic data into real-world looking data, automatically.
So to build our dataset we take the MaskedFace-Net images as domain A, and FFHQ as domain B. This is as simple as putting each domain images into its own directory.
Training
Training is achieved in two steps:
- We build a mask detector with the DeepDetect platform
- We train our mask to face generator with JoliGAN
Training the mask detector is straightforward. The detector is then run on every masked face, and detected mask bounding boxes are used to build rough segmentation zones. These look like the figure below.

Training the GAN is done as follows:
git clone https://github.com/jolibrain/joliGAN.git
cd joliGAN
To visualize live metrics & results while training you need visdom:
pip install visdom
python -m visdom.server -port 8097
Now ready to train the mask to face GAN:
python train.py --dataroot /path/to/dataset/ --checkpoints_dir /path/to/gan_checkpoints/ --name face_masks_removal \
--display_env face_masks_removal --display_freq 100 --print_freq 100 --gpu_ids 0 --lr 0.0001 \
--D_lr 0.0002 --crop_size 256 --load_size 256 --dataset_mode unaligned_labeled_mask \
--model cut_semantic_mask --netG resnet_attn --batch_size 2 --input_nc 3 --output_nc 3 \
--fs_light --no_rotate --out_mask
This tells joliGAN to train a ResNet with attention using a modified version of CUT and enhancements to CyCADA. The trick is that the training algorithm uses the face mask rough location to constrain the GAN in various manner.
Typically this makes the neural network find ways of:
- Modifying the smallest number of pixels between the two domains
- Fusing the generated portion as invisibly as possible into the rest of the face.
Visdom reports live while training:

Inference with DeepDetect
Once it has trained, the model can be exported as JIT and to DeepDetect Server very easily:
python export_jit_model.py --model-in-file /path/to/gan_checkpoints/face_masks_removal/latest_net_G_A.pth --img-size 256
Then inference can use DeepDetect API:
python gen_dd_single_image.py --model-in-path /path/to/gan_checkpoints/face_masks_removal/ --img-size 256 \
--img-in /path/to/img_domain_A.png --img-out /path/to/img_domain_B.png --gpu
Below are few more samples.