This is the second article on time-series with Deep Learning and DeepDetect. It shows how to use a type of deep neural network architecture named NBEATS dedicated to time-series. In our earlier post on time-series with recurrent networks and DeepDetect, we did use LSTMs with DeepDetect, and here we thus focus on more appropriate architectures.
This blog post shows how to obtain much more configurable and accurate time-series forecasting models than with other methods.
It’s used by Jolibrain for its customers, on very large and dense datasets. In the following we use a much simpler NASA time-series dataset to demonstrate the easyness of using these new techniques with DeepDetect and get interested users started quickly.
DeepDetect for timeseries forecasting
DeepDetect allows for quick and very powerful modeling of time series for a variety of applications, including forecasting and anomaly detection.
This serie of posts describes reproducible results with powerful deep network advances such as LSTMs, NBEATS and Transformer architectures.
The DeepDetect Open Source Server & DeepDetect Platform do come with the following features with application to time series:
- Multivariate time series support
- Arbitrary forecast length, for full series and signal forecasting
- Arbitrary backcast length, to make best use of the past patterns to predict the future
- Plug & play state of the art architectures
- Live timeseries visualization both during training and inference
NBEATS, a neural network architecture for time-series forecasting
NBEATS originates from research by Boris Oreshkin and its co-authors at unfortunately short-lived ElementAI. NBEATS is an interesting step in applying deep learning to time series because it crafts an architecture dedicated to time-series.
Previous approach consists in translating sequences (sequences to sequence). Timepoints are given to the network one after the other, and the network updates some internal memory in order to update internal representation of state of the sytem. Then the output is computed using internal state representation and current output.
Recurrent neural network do only this, while LSTM use several different mechanisms to explicitely compute what parts to forget and what parts to update given current input.
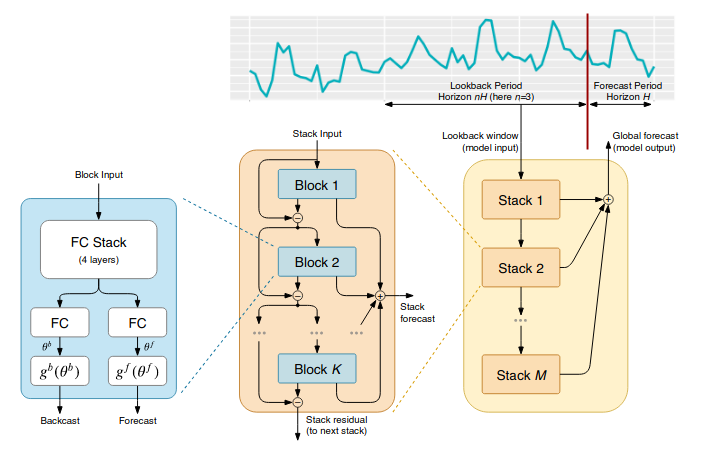
NBEATS use a completely different approach: it take an entire window of past values, and compute many forecast timepoints values in a single pass. For doing so, it uses extensively fully connected layers.
It consists in several blocks connected in a residual way: the first block tries to model past window (backcast) and future (forecast) the best it can, then the second block tries to model only the residual error of the past reconstruction done by the previous block (and also updates the forecast based only on this error) and so on. Such residual architecture allows to stack many blocks without risk of gradient vanishing, and also has the advantages of boosting/ensembling techique (used in classical machine learning): the forecast is the sum of predictions of several blocks, where the first block catches the main trends, the second specializes on smaller errors and so on.
Some specialized trend and frequential blocks also can be used, where the block learn paramaters of given functions, ie polynomial trends and sinus/cosinus with several frequencies.
Such an architecture thus departs from traditional usage of recurrent networks and has several advantages to traditional approaches:
- Faster training: all operations are parallelized on GPUs, making training much faster than with recurrent networks.
- Lightweight networks: NBEATS blocks are much more configurable and thus can yield lighter networks, very useful for small problems or when running on embedded devices.
- Fully configurable backcast and forecast: NBEATS can use arbitrarily long sequences in the past, and forecast arbitrarily in the future. This is configured once for every model, depending on the problem.
The Jolibrain team, who develops DeepDetect, has improved on NBEATS in several ways. The improvements below are all integrated into DeepDetect:
- Multivariate timeseries support: timeseries with multiple signals as input are supported by DeepDetect. The original NBEATS is univariate. Jolibrain has used the multivariate implementation on real-world datasets with up to 800 signals as input (as opposed to a single one for the NASA benchmark).
- Input compression: a configurable compression layer is added to reduce input signal intelligently in the multivariate setting.
- **Architecture considerations: as we prefer training with large batch sizes, our NBEATS tweaked architectures involve less stacks and more blocks. Typically to fit a 11GB GPU with batch size 100 on our own datasets, we use 2 stacks of 5 blocks, as opposed to up to 30 stacks in the original paper.
- Specialized blocks: we find that specialized blocks with sinus/cosinus do not help training, and instead we experiment with other techniques, such as SIREN.
- Hyper-parameters: the number of parameters to tweak can become overwhelming, as the price to pay for more flexibility. DeepDetect absracts away most of them by computing good default values while leaving a degrees of freedom where it matters most.
Timeseries forecasting with DeepDetect using NBEATS
DeepDetect supports timeseries forecasting with its Libtorch backend.
This first post builds a one step ahead forecasting model in just a few lines of code.
For reproducibility we use the time series from NASA benchmarks. It’s interesting that this data originates from Mars rover and orbiter telemetry, as it exhibits both mechanical dynamics and a variety of noises.
The main steps are as follows, and detailed in the rest of the article:
- Dataset setup: prepare a time serie dataset in CSV format
- Model setup: select the model type and main parameters
- Model training: train a model given the forecasting problem parameters
- Model testing: use the model on new or held-out data and study its properties
We created widgets to help model training and evaluation of the predictions. The widgets can be found in dd_widgets:
Requirements
DeepDetect provides Jupyter notebook Python widgets but that can be used independently. The time series widget comes with the DeepDetect platform.
DeepDetect time series visualization widget:
pip install "git+https://github.com/jolibrain/dd_widgets"
pip install "git+https://github.com/jolibrain/deepdetect.git#egg=dd_client&subdirectory=clients/python"
The widgets can be found in dd_widgets:
from dd_widgets import timeseries as ts
from dd_widgets.timeseries.nbeats import NBEATS
Dataset setup
The original dataset can be downloaded from https://github.com/khundman/telemanom#to-run-with-local-or-virtual-environment
The data is stored in a numpy array, and needs to be convert into a CSV file so that DeepDetect can read and preprocess it.
The application under study is a one-step prediction task, thus the CSV must contain:
- A column named
0that contains the input signal
The column 0 is used as input and output (wrt ‘forecast’ value)
The preprocessed dataset can be downloaded from https://www.deepdetect.com/dd/datasets/nasa_smap_msl_dd.tar.gz
DeepDetect setup
Run a DeepDetect Server from Docker or command line. By default it listens on 127.0.0.1:8080.
Model setup
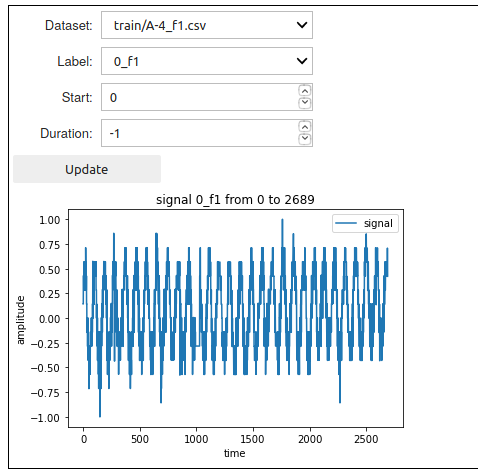
The example below makes use of the A-4_f signal from the NASA dataset, this can be applied to all other signals as well.
datadir = "/path/to/nasa/A-4_f1"
model_name = "nbeats_nasa_a4"
nbeats = NBEATS(
sname = "nbeats_timeseries",
host = "127.0.0.1",
port = 8080,
models_dir = "/path/to/models/",
models = [model_name],
# all columns of the csv
columns = ["0"],
# NBEATS predicts the future from the past: target columns are also input columns
target_cols = ["0"],
# ignored columns. The model won't predict the future of these signals
ignored_cols = [],
# Model parameters
# NBEATS hyperparameters
# 2 x generic stack with theta = 128, 5 blocks per stacks, hidden unit size of 128 everywhere
# more details here https://www.deepdetect.com/server/docs/api/#create-a-service and in NBEATS paper
template_params = ["g128", "g128", "b5", "h128"],
# number of past steps taken as input
backcast = 200,
# number of future steps predicted
forecast = 1,
# Training parameters
gpuid = 0,
batch_size = 100,
iter_size = 1,
iterations = 100000,
# predictions are cached in this directory to save time
output_dir = "/path/to/predictions/",
# root directory of the prediction data
datadir = datadir,
# ts.get_datafiles retrieves all csv files from a directory
datafiles = ts.get_datafiles(datadir)
)
This creates an NBEATS architecture. The architecture has 2 stacks with 5 blocks each. Each block has a hidden unit size of 128. As input it takes the past sequence of 200 values, and forecasts a single future value.
A great property of NBEATS is that this can be easily configured, e.g. taking 200 past values and predicting the 10 next values.
The model is expected to train on GPU with a batch size of 100 and for 100k iterations.
Data lookup
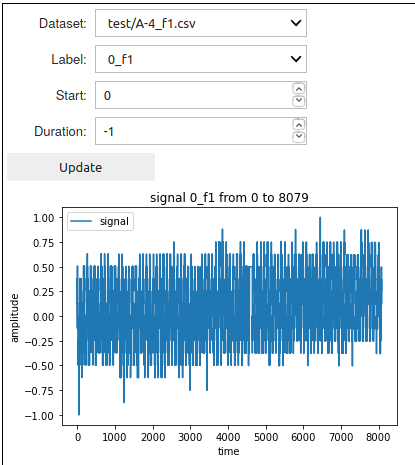
Now that the model has been setup, the DeepDetect time series widget allows the target signal to be visualized with:
nbeats.dataset_ui()
Model training
DeepDetect makes the training step easy and robust. Here to train the model with train dataset located at datadir + "/train" and test dataset located at datadir + "/test":
train_data = [datadir + "/train", datadir + "/test"]
# create a service with name `nbeats.sname` and model `model_name`
nbeats.create_service(model_name)
# train service `nbeats.sname` on data `train_data`
nbeats.train(train_data)
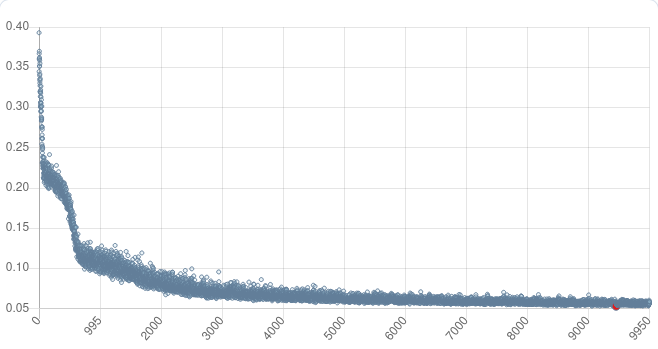
This start training and then returns immediately, while the training job runs in the background. Expect between 30 minutes and one hour for this job, depending on your GPU.
Training metrics can be monitored with the DeepDetect Platform, or with the DeepDetect Server API.

Prediction with NBEATS
Once training has ended, the model is ready to be used for inference on new data.
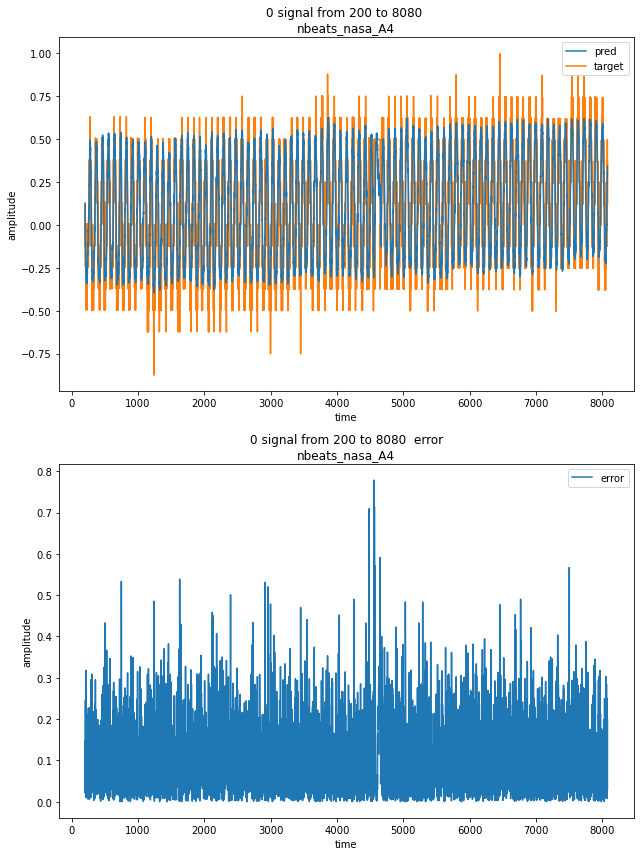
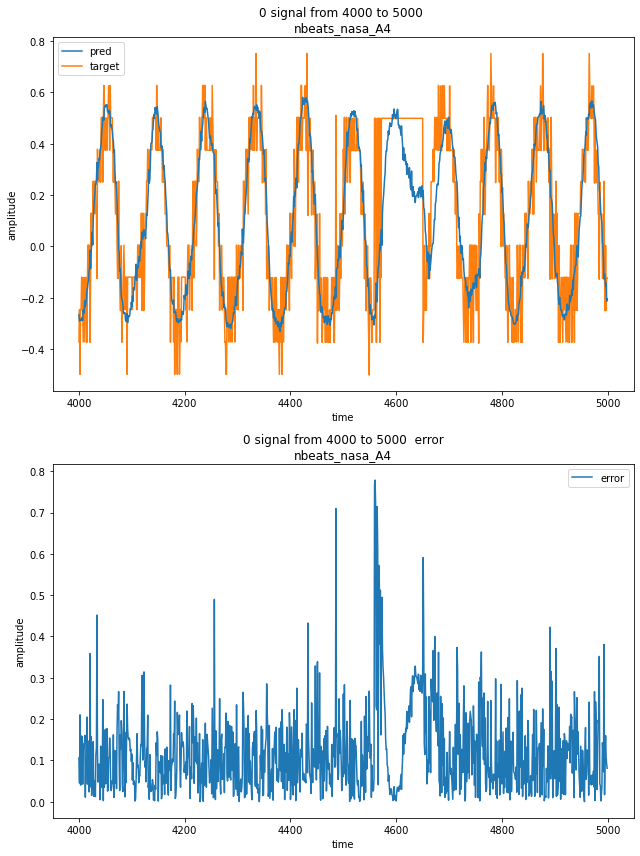
Forecast result can be visualized with the forecast UI:
# With override = False, if predictions have already been
# computed, they are reloaded from the cache.
# If you want to force prediction again, you can set override to True
nbeats.predict_all(override = False)
nbeats.forecast_ui()
This UI displays the target signal alongside with the model prediction, and the resulting error.