Training from text
The DD platform can train from text as:
- documents or sentences
- word-based or character-based
And the following models:
- Neural network or Decision trees from word-based (BoW) features (better suited to documents and small datasets)
- Convolution neural nets from character-based features (better suited to sentences and large datasets)
Data format
The platform has the following format requirements for training from textual data:
- All data must be in plain text format (aka .txt files)
- UTF-8 characters are supported
For document classifications, data should be organized as:
- One directory for each class
- Every directory contains one plain text file per document
E.g. two directories, business and sport, with the relevant text files in each directory. Document classification with one directory per class and one file per document:
mydata/training
mydata/training/business/
mydata/training/business/bus11.txt
mydata/training/business/bus23.txt
...
mydata/training/sport/
mydata/training/sport/sport34.txt
mydata/training/sport/sport98.txt
...
mydata/test/
mydata/test/business/
mydata/test/business/bus234.txt
...
mydata/test/sport
mydata/test/sport/sport321.txt
...
Sentence / short text classification with one directory per class and one line per document:
mydata/training
mydata/training/business/
mydata/training/business/all.txt
mydata/training/sport/
mydata/training/sport/all.txt
mydata/test/
mydata/test/business/
mydata/test/business/all.txt
mydata/test/sport
mydata/test/sport/all.txt
When textual data is made of a very high number of sentences or lines, e.g. tweets, the data are better organized as follows:
- One directory for each class
- Every directory contains a single file in which every line is a text sample for training.
This allows for millions of short texts to be stored and processed more efficiently.
Choose the document or sentence organisation as best for your task.
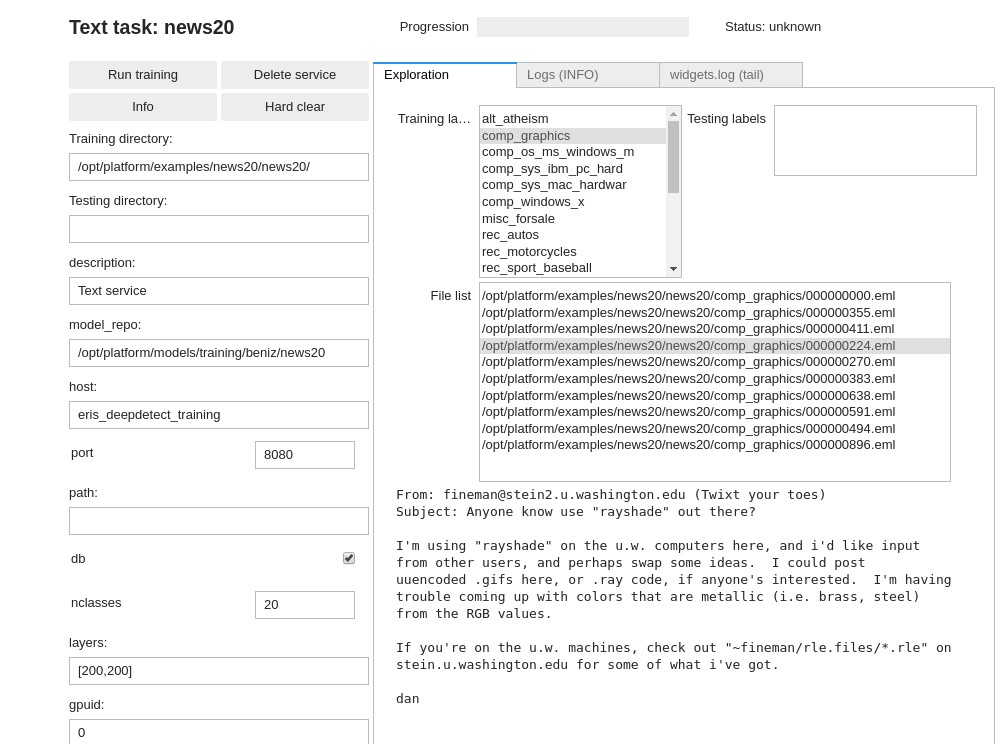
You can review your data from the notebook when preparing for training (see snippets) in sections below.
DD platform comes with a Jupyter UI to review your data:
Neural network for text (BoW)
DD automatically parses and manages the BoW features as well as neural network creation.
Using the DD platform, from a JupyterLab notebook, start from the code on the right.
Neural network Bag-of-Word text classification notebook snippet:
# Neural network for text (BoW)
txt_mlp_train_job = Text(
'news20',
host='deepdetect_training',
port=8080,
training_repo='/opt/platform/examples/news20/news20/',
model_repo='/opt/platform/models/training/JeanDupont/news20/',
nclasses=20,
shuffle=True,
min_count=10,
min_word_length=5,
count=False,
template='mlp',
layers='[200,200]',
activation='relu',
tsplit=0.2,
base_lr=0.001,
solver_type='AMSGRAD',
iterations=10000,
test_interval=500,
batch_size=128
)
txt_mlp_train_job
This prepares a training job named news20 for a two-layers MLP with 200 hidden neurons in every layer, using ReLU activations. The dataset is automatically shuffled and splitted with 80% used for training, and 20% used for testing. Solver is AMSGRAD, learning rate is 1e-3 over 10000 iterations of batches of 128 samples.
Text is automatically pre-processed so that min word size is 5 and words with counts below 10 are ignored, and features are whether a word is present or not (count:false).
See https://deepdetect.com/tutorials/txt-training/ for a more thorough description of some options.
Convolutional networks for text (character-based)
DD automatically parses and managers the BoW features as well as neural network creation.
Using the DD platform, from a JupyterLab notebook, start from the code on the right.
Character-based Convolutional Network for text classification notebook snippet:
# Convolutional network for text (character-based)
txt_convnet_train_job = Text(
'news20_convnet',
training_repo = '/opt/platform/examples/news20/news20/',
testing_repo=None,
host='deepdetect_training',
port=8080,
model_repo="/opt/platform/models/training/JeanDupont/news20_convnet/",
db=True,
nclasses=20,
characters=True,
read_forward=False,
sequence=512,
embedding=True,
template="vdcnn_9",
iterations=10000,
test_interval="1000",
batch_size=128,
base_lr=0.001,
solver_type="AMSGRAD",
tsplit=0.2,
shuffle=True,
target_repository='/opt/platform/models/private/news20_convnet'
)
txt_convnet_train_job
This prepares a training job named news20_convnet.
It uses a VDCNN-9 that is a 9 layers 1-D convolutional network for text. The network reads sequences of 512 characters backwards (i.e. from the end of the text / sentence back to the beginning, up to 512 characters).
The dataset is automatically shuffled and splitted with 80% used for training, and 20% used for testing. Solver is AMSGRAD, learning rate is 1e-3 over 10000 iterations of batches of 128 samples.
Text is automatically pre-processed into characters with embeddings.