Training an OCR
Data format
The DD platform has the following requirements for training from images for OCR:
- All data must be in image format, most encoding supported (e.g. png, jpg, …)
gif images are not supported to avoid label errors when decoding the multiple frames!
A main text file list all images path and their OCR string counterpart, using space as a separator. See on the right for data format and examples
You need to prepare both a
train.txtandtest.txtfile for training and testing purposes.
The name of the train and test file does not matter, though we recommend naming them consistenly across your datasets as it makes code adaptation much easier!
DD platform comes with a custom Jupyter UI that allows testing your OCR dataset prior to training:
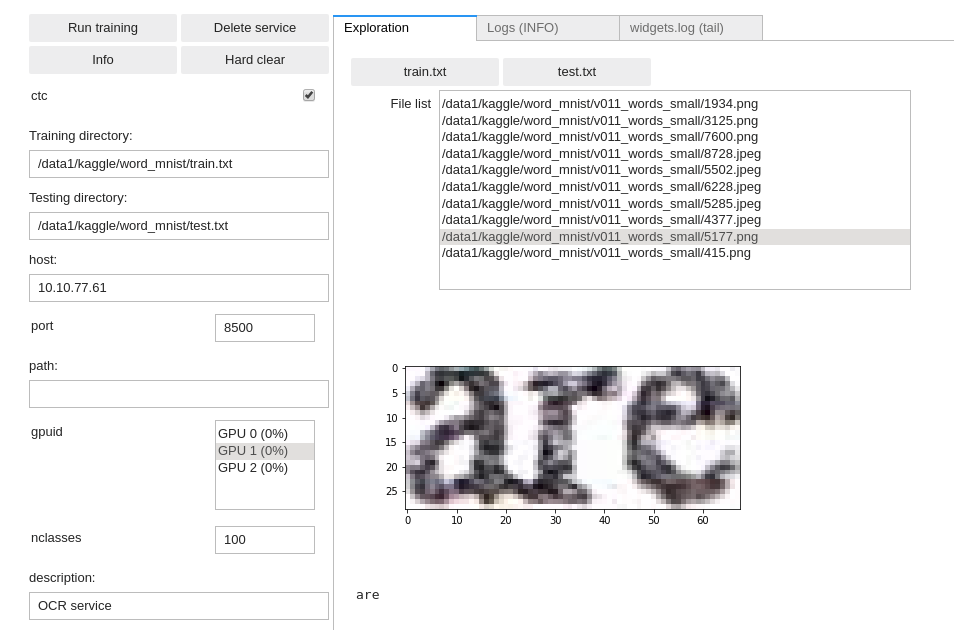
Training an OCR reader
- OCR image & data example

OCR example train.txt file:
/opt/platform/examples/word_mnist/v011_words_small/9281.png possible /opt/platform/examples/word_mnist/v011_words_small/3426.png burgers, /opt/platform/examples/word_mnist/v011_words_small/4901.png bank. /opt/platform/examples/word_mnist/v011_words_small/8.jpeg what /opt/platform/examples/word_mnist/v011_words_small/1547.jpeg OF /opt/platform/examples/word_mnist/v011_words_small/2238.jpeg Littlefield
Using the DD platform, from a JupyterLab notebook, start from the code on the right.
OCR notebook snippet:
ocr = OCR(
'word_mnist',
training_repo='/opt/platform/examples/word_mnist/train.txt',
testing_repo='/opt/platform/examples/word_mnist/test.txt',
host='deepdetect_training',
port=8080,
img_height=80,
img_width=128,
align=False,
model_repo='/opt/platform/models/training/jolibrain/words_mnist',
nclasses=100,
template='crnn',
iterations=10000,
test_interval=1000,
snapshot_interval=1000,
batch_size=128,
test_batch_size=32,
noise_prob=0.001,
distort_prob=0.001,
gpuid=1,
base_lr=0.0001,
solver_type='ADAM',
mirror=False,
rotate=False,
resume=False
)
ocr
This prepares a CNN + dual-LSTM layers deep network with the following parameters:
word_mnistis the example job name
Job names must be unique, replace `word_mnist` with your own
Using job names that reflect your experiments is good practice, e.g. `city_pspnet_iter75k_dice_weighted_amsgrad`
training_repospecifies the location of the data