Similarity search
Overview
DeepDetect Server and Platform come with image and object similarity search built-in. DeepDetect supports two type of image similarity analysis:
Image global similarity search: indexing, search & similarity over full images. This capability is simple and mainstream since the emergence of deep neural networks for images.
Objects in image similarity search: indexing, search & similarity over detected objects within images. This capability is less commonly made available than the one above and is more powerful: it allows to build search engines for objects that are within the images, as opposed to search of globally similar images.
Overall, this is a two step process:
A Deep Learning model is run over images to process the image globally or detect objects. The output are semantic vectors that represent the images or its relevant portions (i.e. objects). These vectors are indexed for later similarity search.
The same deep model is run over new images, and the outputs are used to search the previously built index.
The steps thus are to :
- setup a image processing neural network, either a generic classifier or a more specialized model, for instance a specialized image component detector;
- pass the images to index;
- build the index;
- query the index for similar images.
Once the index is built, any number of queries can be done on the built index. New images can be added to the index at any time. Two indexing backends are available within deepdetect, and are selected at compile time.
- ANNOY : simple and efficient backend, default for binary deepdetect <= 0.9.3.
- FAISS : support a lot of different indexing schemes, support incremental indexing, support indexing on GPU; not so simple to configure for precise needs. Recommended for very large indexes. Available at compile time for deepdetect >= 0.9.4.
The following presupposes that DeepDetect has been built & installed. If compiled from source, it should use -DUSE_SIMSEARCH=ON -DUSE_CAFFE=ON and either -DUSE_ANNOY=ON or -DUSE_FAISS=ON.
Setup
We start by setting up the DeepDetect Server, for instance a GPU setup with Docker that can be adapted as needed.
We then setup the required model.
Image similarity search
Getting a pre-trained model
In this tutorial we will use a standard squeeze and excitation ResNet 50 pretrained for detecting 1000 different classes of images as a feature extractor.
cd /path/to/deepdetect
mkdir models
cd models
mkdir simsearch
cd simsearch
wget https://www.deepdetect.com/models/senets/se_resnet_50/SE-ResNet-50.caffemodel
Setting up the feature extractor service
Let’s start the DeepDetect server:
cd /path/to/deepdetect/build/main
./dede
and create a service:
curl -X PUT "http://localhost:8080/services/simsearch" -d '{
"mllib":"caffe",
"description":"similarity search service",
"type":"unsupervised",
"parameters":{
"input":{
"connector":"image",
"height": 224,
"width": 224
},
"mllib":{
"nclasses":1000,
"template": "se_resnet_50"
}
},
"model":{
"repository":"/path/to/deepdetect/models/simsearch/",
"templates":"/path/to/deepdetect/templates/caffe/"
}
}'
This should yield:
{"status":{"code":201,"msg":"Created"}}
Indexing images
curl -X POST "http://localhost:8080/predict" -d '{
"service":"simsearch",
"parameters":{
"input":{ "height": 224, "width": 224 },
"output":{ "index":true },
"mllib":{ "extract_layer":"pool5/7x7_s1" }
},
"data":["/path/to/image_to_index.png"]
}'
This should yield:
{"status":{"code":200,"msg":"OK"},"head":{"method":"/predict","service":"simsearch",
"time":1434.0},
"body":{"predictions":[{"indexed":true,"last":true,
"vals":[0.0,0.25820794701576235,0.0,....,0.06825697422027588,0.1742493212223053],
"uri":"/path/to/image_to_index.png"}]}}}
The data field can contain directories, they are browsed recursively. Image types can be any type supported by opencv.
About extract_layer
Indexing images using neural network is done not on the image itself, but using values of a feature map, somewhere in the network. The choice of the feature map may cause dramatic changes in the behavior. extract_layer option allows to choose the layer to extract values from (the values are the ones from the ouput blob of the chosen layer.
Guideline : on convolutional networks used for image processing, it is commonly admitted that
- lower layers (layers close from the input image) capture low level local features of the images (ie color patches, contour);
- going further and further of the input leads to more and more global and abstract features;
- The final layer (or few layers) specialize the whole image processing network towards a very precise classification (or detection or segmentation) task.
Following this theory, extracting features from layers :
- close to the input should lead to similarity based on low level local features,
- close to the end should lead to more abstract / semantic similarity.
In the example, we choose the last layer before the fully connected layers that are do the classification job.
More options for FAISS
FAISS indexing backend supports more options, that all go to “output” options:
...
"output": {
"index":true,
"index_gpu":true,
"index_gpuid":0,
"index_type":"IVF20,SQ8",
"train_samples":500,
"ondisk":true,
"nprobe":10
},
...
index_gpuperforms the indexing on GPU, using GPU numberindex_gpuid.index_typeis the type of index to use within FAISS, following FAISS index factory convention. Choosing an index type is not straightforward, see Faiss index guideline. For simple cases with around 1000 images to index, we found ‘IVF20,SQ8’ to offer a very interesting compromise between performance and disk footprint.- many FAISS index types construct precise indexing algorithm by tuning meta-algorithms using a representative sample of data to index. Complex indexes may need a lot of training data.
train_samplescontrols the amount of data to use for training. ondiskask FAISS to put indexes directly on disk using MMAPed files, whereas by default it tries to do everything in memory. This works only for *IVF* types of indexes.nprobeis the number of clusters searched for finding closest neighbors. Defaults to number of cluster / 20. This option works only for *IVF* types of indexes.
Building the index
This step is necessary to dump the index on disk and to ensure it is up to date for searching:
curl -X POST "http://localhost:8080/predict" -d '{
"service":"simsearch",
"parameters":{
"input":{ "height": 224, "width": 224 },
"output":{ "index":false, "build_index":true },
"mllib":{ "extract_layer":"pool5/7x7_s1" }
},
"data":["/full/path/of/one_valid_image_indexed.png"]
}'
Searching for similar content
curl -X POST "http://localhost:8080/predict" -d '{
"service":"simsearch",
"parameters":{
"input":{ "height": 224, "width": 224 },
"output":{ "search_nn": 10, "search": true },
"mllib":{ "extract_layer":"pool5/7x7_s1" }
},
"data":["/full/path/of/image_to_search_for.png"] }'
This should yield:
{"status":{"code":200,"msg":"OK"},"head":{"method":"/predict",
"service":"simsearch","time":1355.0},
"body":{"predictions":[{"nns":[{"dist":0.0,"uri":"image_to_search_for.png"}],
"last":true,
"vals":[0.0,0.25820794701576235,0.0,0.0,0.0014903312548995019,
...,
0.0,0.06825697422027588,0.1742493212223053],
"uri":"/full/path/of/indexed_similar_image.png"}]}}
nns shows the nearest neighbors, it is a list of the search_nn closest neighbors. In this example, the search image is indexed in the database, so it is found with a null distance.
An example of similarity search on the platform:
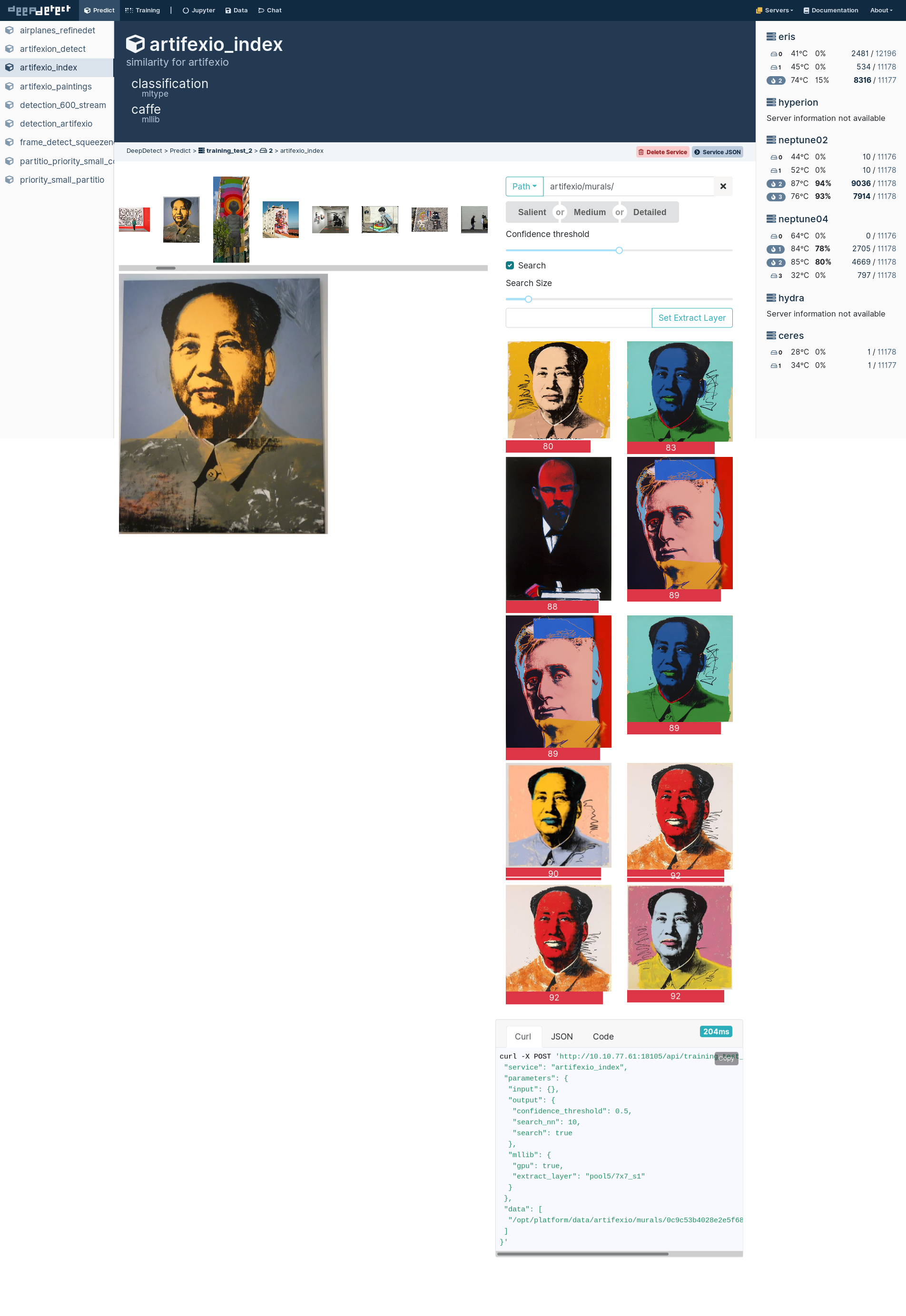
Similar images of a painting.
Advanced topic : Object similarity search
Deepdetect also includes way to detect objects in images and index them directly. Search can be done in order to find closest objects from all indexed images, or images containing most closest objects.
The code for this demo is in deepdetect/demo/objsearch, the specific model being in deepdetect/demo/objsearch/model and some python code lies in deepdetect/demo/objsearch/objsearch_dd.py.
Setting up
cd /path/to/deepdetect
mkdir -p models/objsearch
cd models/objsearch
wget https://deepdetect.com/models/init/desktop/images/detection/detection_201_simsearch.tar.gz
tar xvzf detection_201_simsearch.tar.gz
cd /path/to/deepdetect/build/main
./dede
Creating the service
curl -X PUT "http://localhost:8080/services/objsearch" -d '{
"mllib":"caffe",
"description":"object similarity search service",
"type":"supervised",
"parameters":{
"input":{
"connector":"image",
"height": 300,
"width": 300
},
"mllib":{ "nclasses":201 }
},
"model":{ "repository":"/path/to/deepdetect/models/objsearch/" }
}'
Indexing object from images
curl -X POST 'http://localhost:8080/predict' -d '{
"data": [ "/data/example.jpg" ],
"parameters": {
"mllib": { "gpu": true },
"output": {
"confidence_threshold": 0.1,
"rois": "rois",
"index": true } },
"service": "objsearch" }'
This yields the following results (in this case, with only one object was found):
{"status":{"code":200,"msg":"OK"},
"head":{"method":"/predict","service":"objsearch","time":434.0},
"body":{"predictions":[{"indexed":true,
"rois":[{"last":true,
"bbox":{"xmax":970.8150634765625,"ymax":86.08515930175781,
"ymin":707.6083984375,"xmin":22.640167236328126},
"vals":[204.49110412597657,...,294.74871826171877],
"cat":"car","prob":0.999942421913147}],
"uri":"/full/path/of/example.jpg"}]}}
Building index
curl -X POST 'http://localhost:8080/predict' -d '{
"data": [ "/data/example.jpg" ],
"parameters": {
"mllib": { "gpu": true },
"output": {
"index": false,
"build_index": true,
"rois":"rois" } },
"service": "objsearch" }'
Searching for similar objects
curl -X POST "http://localhost:8080/predict" -d '{
"service":"objsearch",
"parameters":{
"input":{ "height": 300, "width": 300 },
"output":{
"search_nn": 10,
"search": true,
"rois":"rois",
"confidence_threshold": 0.1 } },
"data":["/full/path/of/image_to_search_for.png"] }'
Searching for image that contains the most similar objects
curl -X POST "http://localhost:8080/predict" -d '{
"service":"objsearch",
"parameters":{
"input":{ "height": 300, "width": 300 },
"output":{
"search_nn": 10,
"search": true,
"rois":"rois",
"multibox_roi":true,
"confidence_threshold": 0.1,
"best":1 } },
"data":["/full/path/of/image_to_search_for.png"] }'
Very advanced topic : chaining a detector and an indexer
In first part of this tutorial, we used a vanilla standard network for image processing that is usualy finetuned for a particular task. Generally speaking, training a network for a “proxy” task leads to better results: for instance, finetuning a resnet in order to classify the type of images one wants to index will lead to better results, as the network gets specialized for processing the type of images to index.
Another interesting enhancement is to train a detector of the thing one want to recognize in images, for instance to separate foreground object from background, and to index only the bounding box of the object and not the whole image. This can be done in a nice way using the chain API. In the following, we show how to index regions of interest and not the whole image. This can be done using detection models (that output the regions of interest), like detection_600.
Preparing the directories and launching dede:
cd /path/to/deepdetect
mkdir models
cd models
mkdir -p simsearch/detection
mkdir -p simsearch/index
cd simsearch/detection
wget https://www.deepdetect.com/models/init/desktop/images/detection/detection_600.tar.gz
tar xvzf detection_600.tar.gz
cd ../index
wget https://www.deepdetect.com/models/senets/se_resnet_50/SE-ResNet-50.caffemodel
cd /path/to/deepdetect/build/main
./dede
Creating the detection service
curl -X PUT "http://localhost:8080/services/detection" -d '{
"mllib":"caffe",
"description":"similarity search service detection",
"type":"supervised",
"parameters":{
"input":{
"connector":"image",
"height": 300,
"width": 300 },
"mllib":{ "nclasses":601 },
"output":{ "confidence_threshold":0.3, "bbox": true }
},
"model":{ "repository":"/path/to/deepdetect/models/simsearch/detection" } }'
Creating the indexer service
curl -X PUT "http://localhost:8080/services/index" -d '{
"mllib":"caffe",
"description":"similarity search service index",
"type":"unsupervised",
"parameters":{
"input":{
"connector":"image",
"height": 224,
"width": 224
},
"mllib":{
"nclasses":1000,
"template": "se_resnet_50"
}
},
"model":{
"repository":"/path/to/deepdetect/models/simsearch/index",
"templates":"/path/to/deepdetect/templates/caffe/"
} }'
We thus have two services : an extractor of objects in the image, and a feature extractor that will index the images.
Detecting and indexing in one pass
We can now chain two calls in order to index all bounding boxes and not the whole image:
curl -X PUT "http://localhost:8080/chain/detect_index" -d '{
"chain": {
"resource": "predict",
"calls": [
{
"service": "detection",
"parameters": {
"input": { "connector":"image", "keep_orig":true},
"output": { "confidence_threshold": 0.3, "bbox":true },
"mllib": { "gpu":true}
},
"data": ["/full/path/of/image_to_index.jpg"]
},
{
"action": {
"type": "crop",
"parameters":{
"padding_ratio": 0.025
}
}
},
{
"service": "index",
"parameters": {
"mllib":{ "extract_layer":"pool5/7x7_s1" },
"output": {
"index":true,
"index_gpu":true,
"index_gpuid":0,
"index_type":"IVF20,SQ8",
"train_samples":500,
"ondisk":true
} } } ] } }'
Building the index
curl -X POST "http://localhost:8080/predict" -d '{
"service":"index",
"parameters":{
"input":{ "height": 224, "width": 224 },
"output":{ "index":false, "build_index":true },
"mllib":{ "extract_layer":"pool5/7x7_s1" } },
"data":["/full/path/of/one_valid_image_indexed.png"] }'
Searching for objects similar to an image
curl -X POST "http://localhost:8080/predict" -d '{
"service":"index",
"parameters":{
"input":{ "height": 224, "width": 224 },
"output":{ "search_nn": 10, "search": true },
"mllib":{ "extract_layer":"pool5/7x7_s1" } },
"data":["/full/path/of/image_to_search_for.png"] }'
Searching for objects similar to objects of an image
We first detect object on the query image, then crop and search:
curl -X PUT "http://localhost:8080/chain/detect_search" -d '{
"chain": {
"resource": "predict",
"calls": [
{
"service": "detection",
"parameters": {
"input": { "connector":"image", "keep_orig":true},
"output": { "confidence_threshold": 0.3, "bbox":true },
"mllib": { "gpu":true}
},
"data": ["/full/path/of/image_to_search"]
},
{
"action": {
"type": "crop",
"parameters":{ "padding_ratio": 0.025 } }
}
{
"service": "index",
"parameters": {
"output": { "index" : false, "search" : true }
} } ] } }'